Why AI, ML and Big Data are probably NOT the answer to your business problem
Machine learning, artificial intelligence, big data, in-memory processing, parallel computing, distributed databases, predictive modelling … your social media timelines are full of buzzwords trumpeting how brilliant & revolutionary all this new tech is.
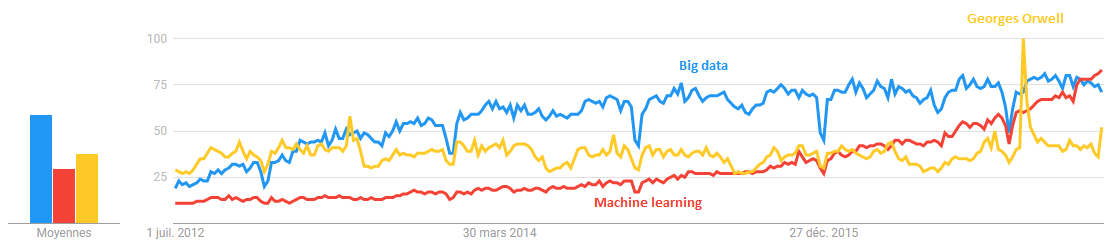 Google search trends for big data, machine learning and … Georges Orwell for scale 😉
Google search trends for big data, machine learning and … Georges Orwell for scale 😉
So what is it all about?
Well, in simple words:
- “Big data” is basically the ability to store and process large volumes of data in a reasonable time frame. It was democratized by two factors which are :
- Public access to parallel computing frameworks that run on commodity hardware: Hadoop-like frameworks can run on pretty much any machine and OS
- A significant drop in storage and calculation power prices.
Using big data environments requires some sharp IT skills imposed by the need to distribute calculations among multiple computers or servers. Those are programming languages like Hadoop MapReduce, Spark, etc.
 Buzzwords will buzz
Buzzwords will buzz
- Machine learning & AI is a trendy word for statistical modelling methods. Think of it as the superb and powerful combination of applied mathematics and scientific programming. the expression “machine learning” is usually used for rather exotic modelling techniques i.e not classic linear models. An important thing to mention here is that ML in itself is the less valuable phase of creating value from data : good modelling is all about data cleansing & enrichment. Anyone can throw a bunch of raw data at a full-automatic ML algorithm, but very few professionals can build solid prediction models that can be used for real life situations. Forget the tech, it’s all about research, experience & industry knowledge 😊
In 2017 and whatever your industry is, you probably already heard these words at work. Your company is thinking about “getting into the big data & AI era” or already experimenting with it.
Let’s start with big data, is it really a good idea to get yourself a Spark cluster ? You can answer it using this magnificent flowchart I just made:
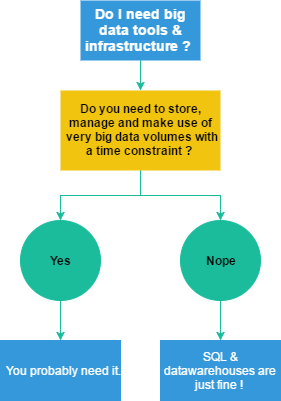 Simple huh?
Simple huh?
Let’s make it clear: not all organizations need big data tech & infrastructures. Of course businesses like large retailers, banks and large public software companies (Airbnb, Netflix, Twitter) managing huge amounts of consumer data and depending on its usage to deliver value can surely benefit from it. But hey, most companies (think 90%) simply don’t need that kind of computational power simply because costs would be far beyond gains. Most companies have a few terabytes of actionable data that live happily on up-to-date good ol’ SQL servers. Relational databases are great because they are easy to maintain and use and benefit from a mature software ecosystem : relational databases are battle-tested technology with very short development time! SQL talent is cheap and available. Stick with relational databases if you can.
Migrating your 1.5TB of data from PostgreSQL into a brand new 35-node Spark cluster on AWS aka OVERKILL:
{kind=link}
‘Big data’ is one of the most confusing industry terms at the moment and the new el Dorado of cloud and IT consulting firms and editors. So yeah, with that much marketing involved, big data can be a pitfall. Here’s why:
- Big data? how about smart data? storing data that is not intended to be used to solve any specific real problem EVER is a bad idea. think about collecting and fully exploiting the RIGHT data, it’s usually not THAT big 😉
 Interesting point of view … read it here https://goo.gl/D88obx
Interesting point of view … read it here https://goo.gl/D88obx
- Deploying & managing big data infrastructures is rather painful and costs lots of cash. If you are not willing to use it on a large scale, it probably is a total waste of resources.
 Yes, please.
Yes, please.
How about some fancy machine learning? Convolutional Neural Networks sound so cool!
Oh, here’s another big buzzword. Isn’t it a bit overhyped too?
Well, machine learning is cool indeed, and generally works wonders with real value creation … when it’s done right and with purpose in mind 😊
Most data scientists will use the same automatic approach regardless of the data, without even deeply understanding the underlying structures and dependencies of it. The results are often mitigated: they lack performance or can’t be generalized to new data. Good predictive modelling is actually 95% «boring stuff» like data cleansing, visualization and exploration, some deep research about the data, how it was generated or harvested, the meaning of the features (variables), etc.
Then comes the modelling part which involves doing a critical choice: the modelling technique.
 “Just go for automatic feature selection Random Forest”
“Just go for automatic feature selection Random Forest”
Which is nowadays usually Random Forest, XGBoost or neural networks, but hey wait a second !
The main problem with machine learning is that very few IT departments can actually deploy it to production because of centralized enterprise legacy systems. The problem is slowly being solved via the adoption of APIs and microservices but it’s still out there in many organizations with older information systems.
 “We will schedule a set of meetings in order to study the possibility of translating your model into proper COBOL”
“We will schedule a set of meetings in order to study the possibility of translating your model into proper COBOL”
In order to avoid production frustration, three essential criteria should be considered before choosing a model:
- Need for interpretability: is it okay if nobody understands what your model actually is? Is it okay if it has no coefficients? No explicit expression? How comfortable is management with abstraction? (You already know the answer to this one).
- Ease of deployment to production: deploying a logistic model to production is easy, it’s all about combining variables while applying weights (coefficients). When it comes to more advanced machine learning models, it’s a whole new thing. Try translating a R deep learning model to Java or C++ (protip: you can’t).
- Performance: how accurate does your prediction have to be? are you trying to predict a patient’s reaction to radiation treatment? or are your forecasting soccer scores? do you need to be real-time-fast? or are you more of a night batch processing guy?
Here’s my advice on this: most of us don’t need to process images, natural language, video streams. We have good old tabular data with many numeric and character features and an output we need to predict. Please, just keep it simple and go with understandable, familiar, easily deployable, fast solutions. 95% of your business problems can be solved with linear models & affiliated techniques like ridge, lasso, splines. And I am not exaggerating here. "Linear" models are super-fast to train and use, 100% understandable, easy to code and maintain: they’re powerful, awesome and you should use them every time you can do so ! Always start simple by trying linear & tree-based models before going for more complicated stuff, your future self will be grateful 😉
Also, from my point of view, data science departments should talk more with IT and have a clear vision of production architectures. All developments must be done with deployment in mind, simply because this is the most efficient approach (DevOps?).
Bottom line: avoid overkill & the waste of resources..
- With so much clickbait-style articles, disguised advertising and obfuscated pre-sales speech, it’s hard to choose a data trajectory, but how about some common sense ?
- Go for big data tech only if your activity requires that kind of power and speed.
- Try not to follow the machine learning hype: “simple” methods are good enough to solve 95% of your problems in an efficient and elegant way. If a logistic or linear regression doesn’t do the job, go for trees. Still nothing ? get your R or Python ready for fun !
Anas EL KHALOUI.